Abstract
Recent advancements in Large Language Models (LLMs) have largely focused on depth scaling, where a single agent solves long-horizon problems with multi-turn reasoning and tool use. However, as tasks grow broader, the key bottleneck shifts from individual competence to organizational capability. In this work, we explore a complementary dimension of width scaling with multi-agent systems to address broad information seeking. Existing multi-agent systems often rely on hand-crafted workflows and turn-taking interactions that fail to parallelize work effectively. To bridge this gap, we propose WideSeek-R1, a lead-agent–subagent framework trained via multi-agent reinforcement learning (MARL) to synergize scalable orchestration and parallel execution. By utilizing a shared LLM with isolated contexts and specialized tools, WideSeek-R1 jointly optimizes the lead agent and parallel subagents on a curated dataset of 20k broad information-seeking tasks. Extensive experiments show that WideSeek-R1-4B achieves an item F1 score of 40.0% on the WideSearch benchmark, which is comparable to the performance of single-agent DeepSeek-R1-671B. Furthermore, WideSeek-R1-4B exhibits consistent performance gains as the number of parallel subagents increases, highlighting the effectiveness of width scaling.
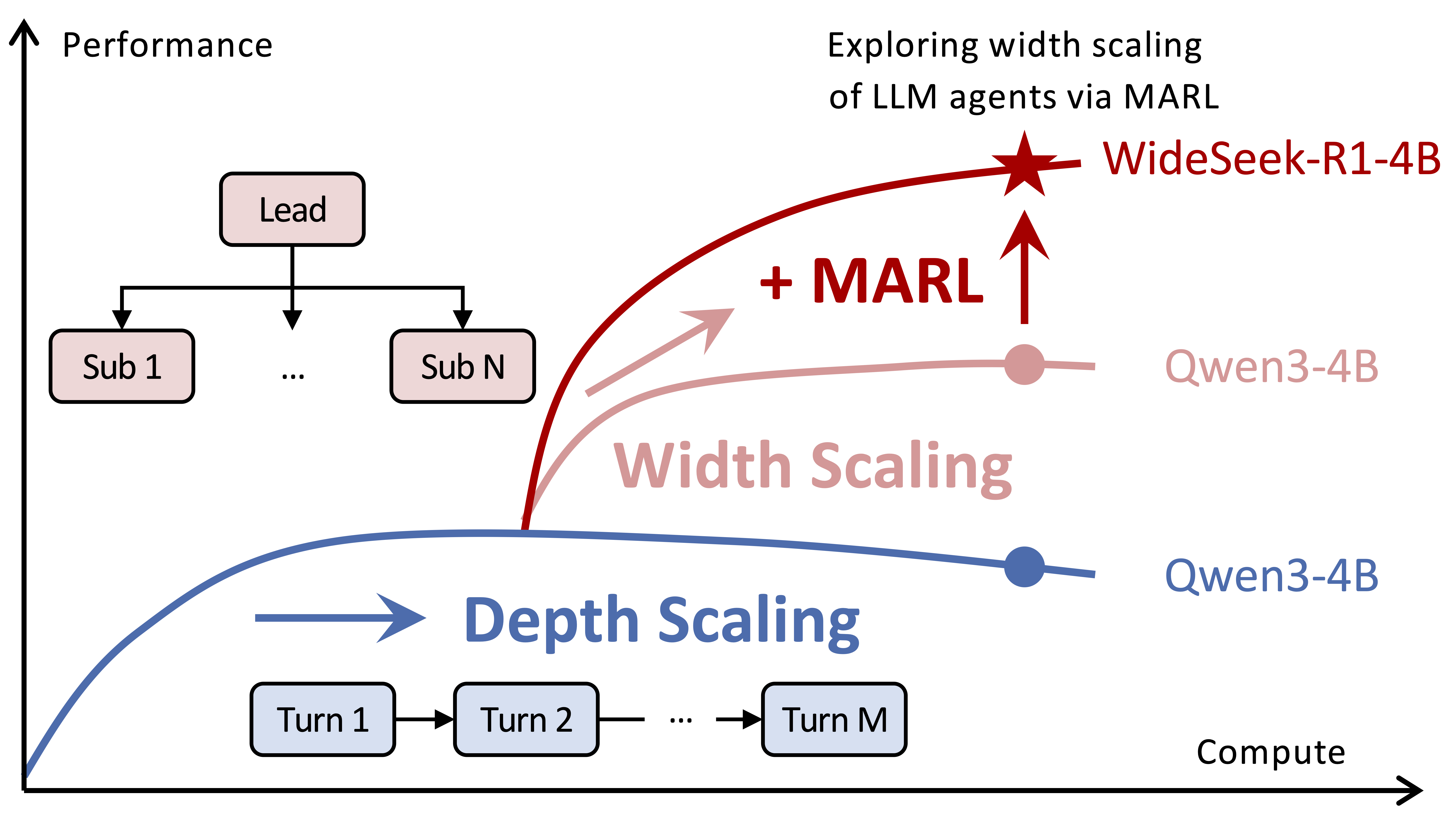
Figure 1: Comparison of depth and width scaling. While depth scaling enhances performance through sequential multi-turn interactions, width scaling orchestrates multi-agent systems for parallel execution. WideSeek-R1 pushes the frontier of width scaling via MARL for synergized orchestration and execution.
Contributions
- We introduce WideSeek-R1, a multi-agent system trained via MARL to synergize scalable orchestration and parallel execution for broad information seeking.
- We open-source a large-scale dataset of 20,000 broad information-seeking tasks, offering a complementary training resource to existing multi-hop datasets.
- We demonstrate the effectiveness of width scaling with WideSeek-R1-4B, which achieves comparable performance to DeepSeek-R1-671B and exhibits consistent gains as the number of parallel agents increases.
Motivation
As tasks grow broader, width scaling via multi-agent systems becomes essential, yet both single-agent methods and existing multi-agent systems fall short in different ways. Broad information seeking, which requires gathering and synthesizing attributes of multiple entities into a structured table, serves as an ideal testbed for this challenge.
Limitations of Single-Agent Methods
Single-agent methods face two fundamental limitations when tasks grow in breadth.
- Context pollution. As the agent's context accumulates information from previous subtasks, irrelevant content increasingly interferes with reasoning, degrading performance on later subtasks.
- Sequential execution. A single agent must process independent subtasks one by one, leaving parallelizable work serialized and making the overall process inefficient.
These limitations underscore the necessity of multi-agent systems, which naturally enable context isolation and parallel execution for effective width scaling.
Limitations of Existing Multi-Agent Systems
Despite their promise, existing multi-agent systems have yet to fully realize the potential of width scaling, primarily because few are trained end-to-end to learn scalable orchestration and parallel execution.
- Hand-crafted orchestration. Most prior work relies on manually designed workflows rather than learned agents, hindering flexible and scalable coordination as the number of agents grows.
- Turn-taking execution. Current systems typically process subtasks one at a time through turn-taking interactions, serializing progress and failing to parallelize independent work.
As a result, the performance of existing multi-agent systems is bottlenecked by limited scalability and insufficient parallelization. WideSeek-R1 is designed to address both levels through end-to-end multi-agent reinforcement learning.
Method
WideSeek-R1 is a hierarchical lead-agent–subagent system trained via end-to-end MARL to synergize scalable orchestration and parallel execution for width scaling. The lead agent and subagents share a single LLM but operate with isolated contexts and specialized tools: the lead agent focuses on task decomposition and orchestration, while each subagent executes its assigned subtask in parallel using external tools to gather information and return findings.
Figure 2. Overview of WideSeek-R1 rollout and training pipeline. Rollout: The lead agent coordinates task decomposition while subagents execute parallel subtasks. Training: A shared model is trained via GRPO with multi-agent advantage assignment and dual-level advantage reweighting.
Lead Agent for Scalable Orchestration
The lead agent is responsible for decomposing a broad task into parallelizable subtasks and delegating
them to subagents. Unlike existing multi-agent systems that rely on hand-crafted workflows, our lead agent
is trained to perform scalable and learnable orchestration, enabling flexible coordination
as the number of subagents increases. The only tool available to the lead agent is
call_subagent, which we intentionally restrict to avoid context pollution.
Subagents for Parallel Execution
The subagents are responsible for parallel information seeking, enabling width scaling by
executing multiple subtasks simultaneously. This design addresses the context pollution and sequential
execution bottlenecks that plague single-agent methods. The subagents are equipped with two tools:
search, which retrieves relevant snippets and URLs for a given query; and access, which generates a summary from a specific URL.
Multi-Agent Reinforcement Learning
We jointly optimize the lead agent and subagents through end-to-end MARL with a shared model, enabling the simultaneous learning of orchestration and information-seeking behaviors. Our method builds upon GRPO and extends it for multi-agent systems with two key designs:
- Multi-Agent Advantage Assignment: To ensure training stability and prevent reward hacking, we use a verifiable outcome reward for each multi-agent rollout and assign the same advantage to all agents and all tokens.
- Dual-Level Advantage Reweighting: To better handle multi-agent, multi-turn training of LLMs, we consider both agent-level and token-level advantage reweighting mechanism within the policy gradient objective.
Training Data Construction
To unlock the potential of width scaling, WideSeek-R1 requires a substantial volume of broad information-seeking tasks. We develop a fully automated data construction pipeline to synthesize high-quality training instances consisting of schema-constrained queries and standardized tabular outputs, yielding a large-scale dataset of 20,000 instances.
Figure 3. Overview of the automated data construction pipeline with three stages: Query Generation, Answer Generation, and QA Pair Filtering.
Our pipeline operates in three key stages:
- Query Generation: We extract user intents from HybridQA and refine them into complex, schema-constrained queries that mandate specific table structures and broad coverage.
- Answer Generation: We prompt the model to generate two responses independently along with the unique column(s), enabling self-consistency verification.
- QA Pair Filtering: We rigorously screen the data by discarding instances with low consistency or insufficient difficulty, ensuring that only robust and challenging samples remain in the final dataset.
Experiment Results
Main Results on WideSearch
WideSeek-R1-4B achieves the best results on five out of six metrics among 4B and 8B baselines. The multi-agent system consistently outperforms the single-agent variant with an absolute improvement of 11.9% in item F1 score, and attains an 8.8% gain over the base Qwen3-4B in the same multi-agent setting. Notably, WideSeek-R1-4B achieves performance comparable to single-agent DeepSeek-R1-671B despite using nearly 170× fewer parameters.
| Setting | Model | Item F1 Score (%) | Row F1 Score (%) | Success Rate (%) | |||
|---|---|---|---|---|---|---|---|
| Avg@4 | Max@4 | Avg@4 | Max@4 | Avg@4 | Pass@4 | ||
| Single Agent |
SingleSeek-R1-4B | 28.1 | 39.2 | 6.5 | 12.5 | 0.3 | 1.0 |
| Qwen3-4B | 20.1 | 30.2 | 3.0 | 4.8 | 0.0 | 0.0 | |
| Search-R1-7B | 15.5 | 24.4 | 2.0 | 4.4 | 0.0 | 0.0 | |
| ASearcher-7B | 16.5 | 26.0 | 2.8 | 5.8 | 0.0 | 0.0 | |
| DeepSeek-R1-671B | 41.3 | 55.1 | 20.7 | 31.7 | 0.4 | 1.5 | |
| Multi-Agent System |
WideSeek-R1-4B | 40.0 | 51.8 | 15.3 | 24.4 | 0.4 | 1.0 |
| Qwen3-4B | 31.2 | 42.3 | 8.4 | 15.5 | 0.0 | 0.0 | |
| AgentFlow-7B | 28.7 | 45.4 | 9.0 | 20.2 | 0.4 | 1.5 | |
| OWL-8B | 20.2 | 29.3 | 3.1 | 5.8 | 0.0 | 0.0 | |
| MiroFlow-8B | 23.7 | 37.7 | 5.8 | 12.7 | 0.4 | 1.0 | |
Table 1. Results on the WideSearch benchmark with 100 English and 100 Chinese broad information-seeking tasks requiring tabular output.
Exploring Width Scaling
To compare with depth scaling and illustrate the width scaling property of WideSeek-R1, we plot the performance curves with respect to test-time compute, including number of turns for depth scaling and number of agents for width scaling.
- Depth Scaling: Performance initially improves with more turns but quickly plateaus, as the single agent is bottlenecked by its fixed context length.
- Width Scaling: Performance initially improves with more subagents but begins to decline at ten, as noise from conflicting responses overwhelms the untrained lead agent's ability to aggregate information.
- Width Scaling + MARL: Performance improves consistently with the number of subagents, pushing the frontier to 40% item F1 score with 10 subagents, demonstrating the effectiveness of MARL in jointly optimizing orchestration and parallel execution.
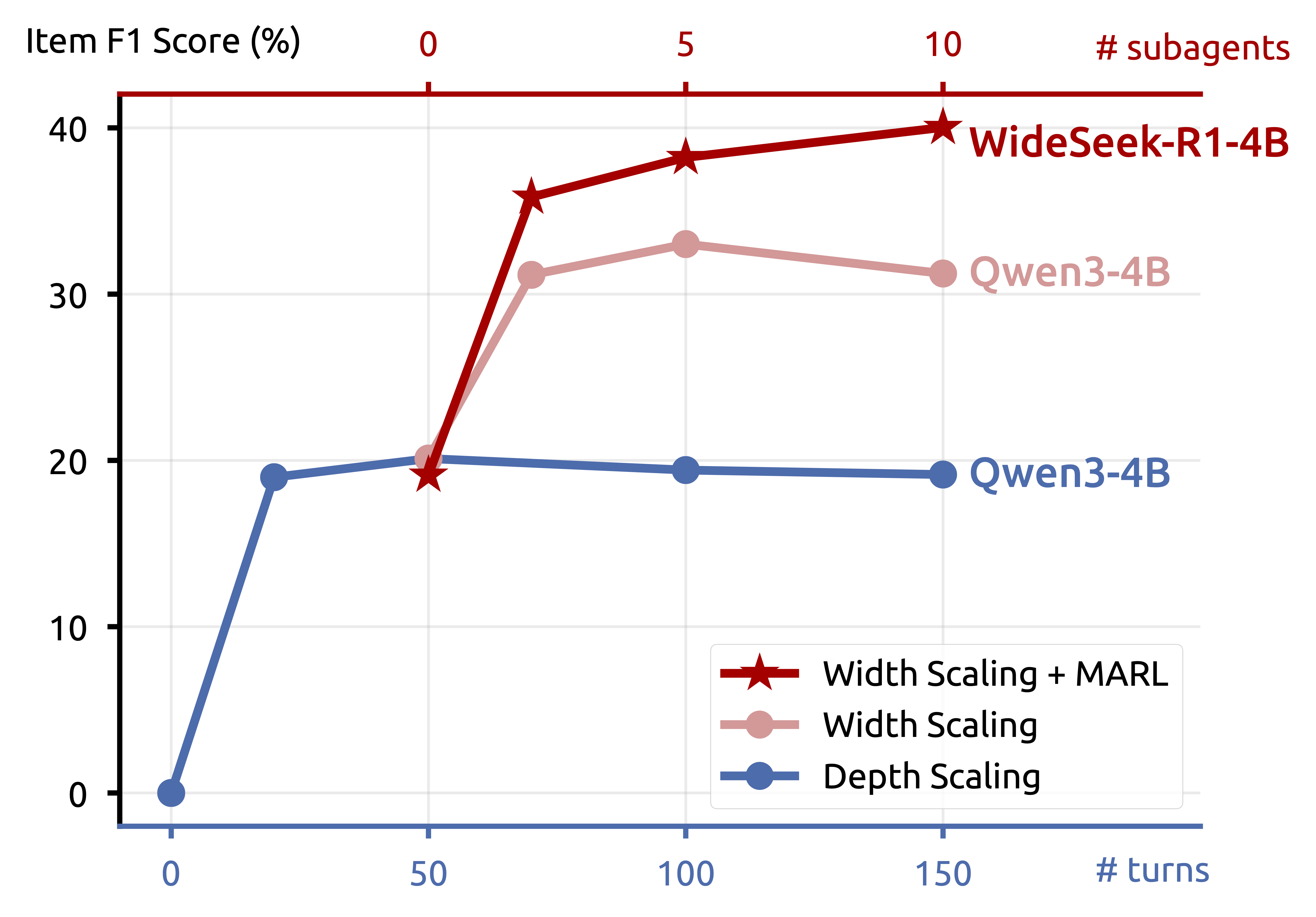
Figure 4. Comparison of depth and width scaling with respect to (w.r.t.) test-time compute. The blue curve shows depth scaling w.r.t. the number of turns (bottom axis), while the two red curves show width scaling w.r.t. the number of subagents (top axis).
Ablation Studies
We conduct ablation studies to dissect the key components of our framework, aiming to answer two primary questions: (1) Is the joint optimization of both the lead agent and subagents necessary for optimal performance? (2) How does our constructed dataset impact the model's overall capability?
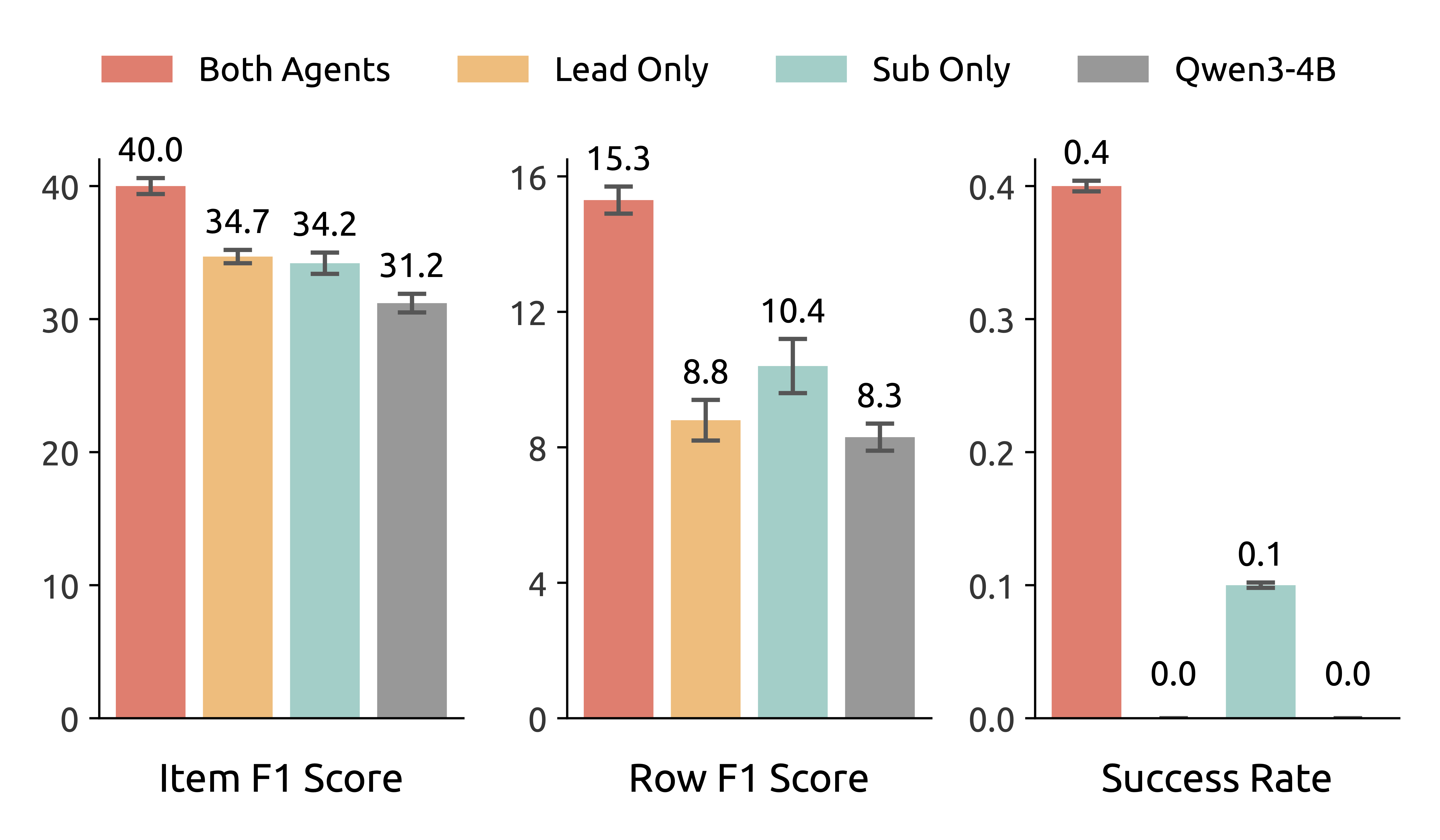
Figure 5. Ablation on lead agent and subagents.
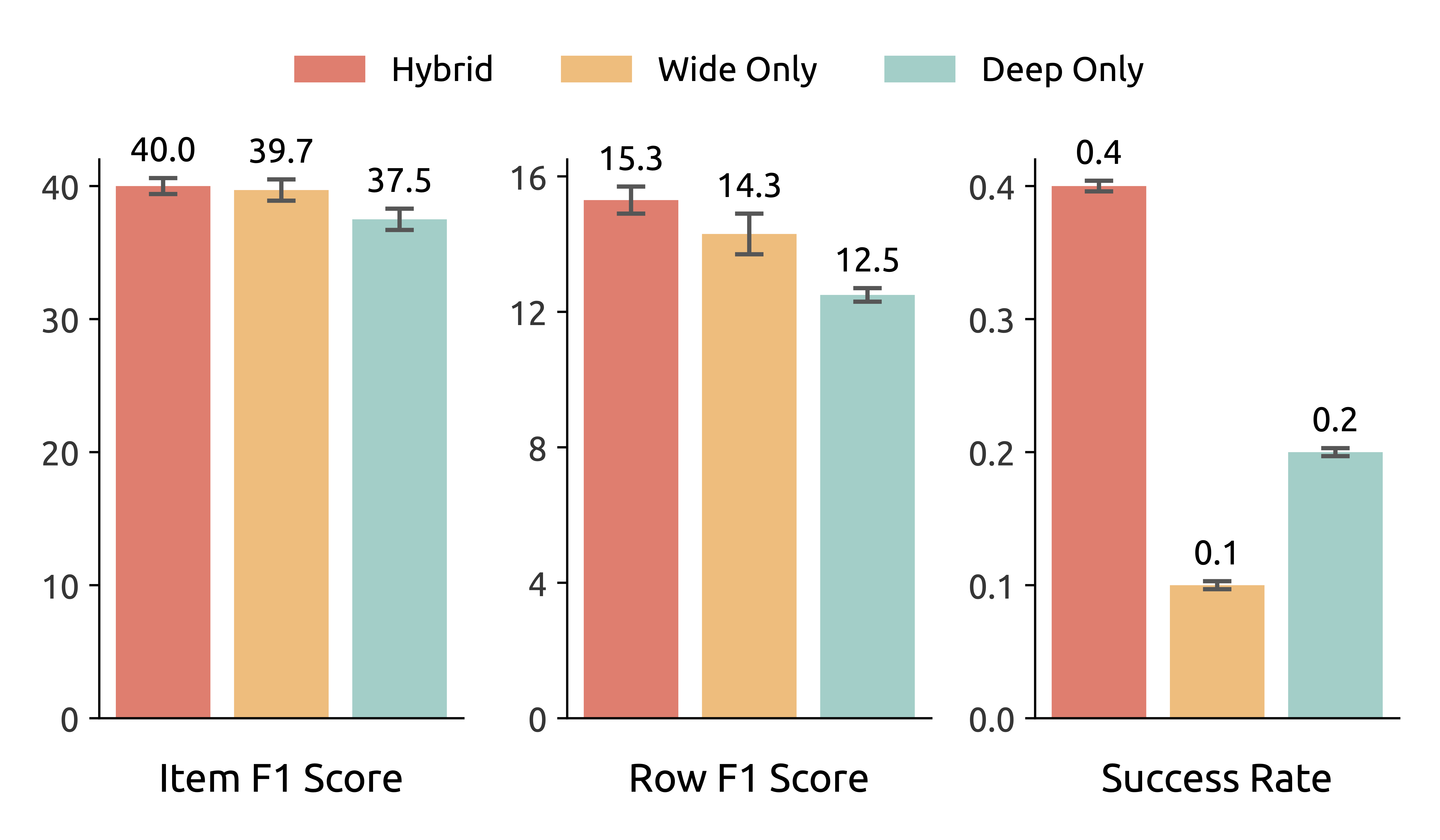
Figure 6. Ablation on training data composition.
Lead Agent and Subagents (Left). We evaluate four settings by assigning either WideSeek-R1-4B or Qwen3-4B to each role. The best performance is achieved when both roles use WideSeek-R1-4B, and upgrading either role alone yields comparable gains, confirming that MARL effectively enhances both orchestration and subtask execution. The further gains from combining both roles highlight the synergy between these capabilities and validate the importance of end-to-end training.
Training Data (Right). We compare models trained on wide-only, deep-only, and hybrid datasets of equal size. The model trained on the hybrid dataset consistently outperforms those trained on either wide-only or deep-only dataset across all metrics, indicating that wide and deep data provide complementary benefits: wide data helps the system learn effective orchestration, while deep data enhances information-seeking and subtask execution.
Standard QA Benchmarks
To assess the versatility of WideSeek-R1 beyond broad information seeking, we evaluate it on seven standard open-domain QA benchmarks spanning three single-hop datasets and four multi-hop datasets. WideSeek-R1-4B achieves an average score of 59.0%, outperforming its backbone multi-agent Qwen3-4B by 7.7% and surpassing larger multi-agent systems like OWL-8B and MiroFlow-8B, validating that our MARL framework enhances width scaling without compromising general tool-use capabilities.
| Setting | Model | Average | Single-Hop | Multi-Hop | |||||
|---|---|---|---|---|---|---|---|---|---|
| NQ | TriviaQA | PopQA | 2Wiki | HotpotQA | Bamboogle | MuSiQue | |||
| Single Agent |
SingleSeek-R1-4B | 57.0 | 58.8 | 78.3 | 48.0 | 70.9 | 62.1 | 54.6 | 26.5 |
| Qwen3-4B | 48.3 | 48.5 | 68.7 | 43.0 | 58.9 | 51.4 | 48.2 | 19.2 | |
| Search-R1-7B | 55.4 | 49.9 | 78.0 | 55.7 | 58.1 | 60.8 | 58.4 | 27.1 | |
| ASearcher-7B | 61.0 | 54.5 | 79.3 | 55.9 | 77.6 | 67.6 | 60.0 | 32.6 | |
| Multi-Agent System |
WideSeek-R1-4B | 59.0 | 56.1 | 78.5 | 48.5 | 75.0 | 64.2 | 61.8 | 28.9 |
| Qwen3-4B | 51.3 | 49.6 | 70.7 | 44.9 | 65.0 | 54.3 | 52.6 | 21.7 | |
| AgentFlow-7B | 61.0 | 58.5 | 87.0 | 52.5 | 77.2 | 57.0 | 69.6 | 25.3 | |
| OWL-8B | 57.2 | 64.0 | 74.2 | 52.2 | 62.6 | 61.0 | 55.8 | 30.4 | |
| MiroFlow-8B | 50.0 | 50.9 | 73.1 | 42.8 | 58.6 | 52.4 | 50.8 | 21.3 | |
Table 2. Results on standard QA benchmarks including three single-hop and four multi-hop benchmarks.
BibTeX
@article{xu2026wideseek,
title={WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning},
author={Xu, Zelai and Xu, Zhexuan and Zhang, Ruize and Zhu, Chunyang and Yu, Shi and Liu, Weilin and Zhang, Quanlu and Ding, Wenbo and Yu, Chao and Wang, Yu},
journal={arXiv preprint arXiv:2602.04634},
year={2026},
}